When I read the README of Flux, I found it difficult to get the point of the following section:
We originally set out to deal correctly with derived data: for example, we wanted to show an unread count for message threads while another view showed a list of threads, with the unread ones highlighted. This was difficult to handle with MVC — marking a single thread as read would update the thread model, and then also need to update the unread count model. These dependencies and cascading updates often occur in a large MVC application, leading to a tangled weave of data flow and unpredictable results.
Seriously, why it is “difficult to handle with MVC”?
While different people have different understand of the old MVC, the typical structure looks like V to C has a 1 to 1 map and M to V/C has a 1 to many map. It works so good if the structure make sense. What makes it difficult is actually when you want to have a 1 to 1 map for M to V/C and all the Ms needs a machanism to be kept synced.
Say, for example, we have only one model for the two views - “an unread count for message threads” and “a list of threads, with unread ones highlighted”. It is not SO difficult because when makring a single thread as read we can update the only one model, and it will not lead to “a tangled weave of data flow” or unpredictable results”.
Hmm, so why will one want to MAKE it difficult?
No, noboday want to make it difficult. Just by have two separate models for the two views make it a lot simple to understand. Yes, we just want to make it SIMPLE rather than DIFFICULT. In the following diagram, Controller disappears (sort of merged into View), Store is nothing more than Model.
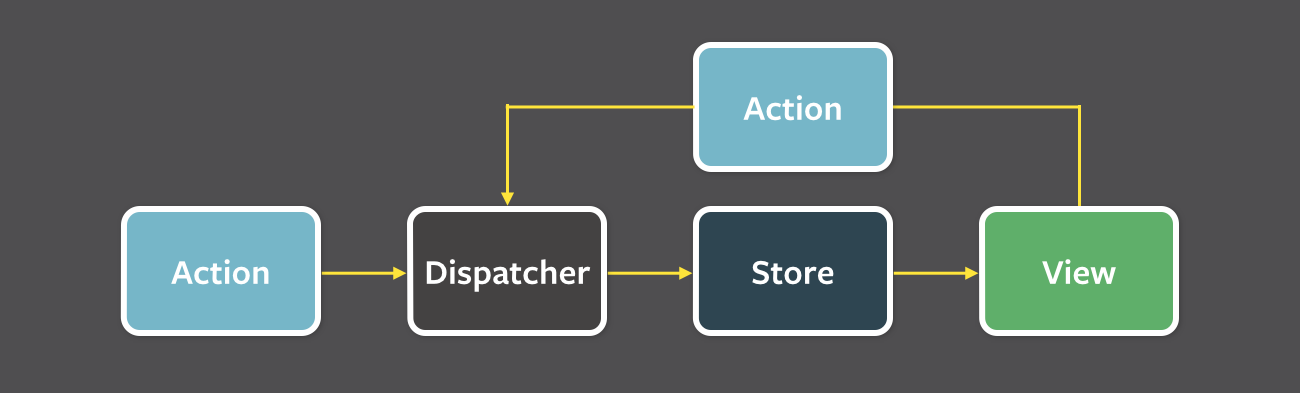
However, we need a machanism to keep the two models synced. We have tones of ways to - create reference between each other, having another model refer to them, event-based synchorization, etc. We will discuss two options below.
Option 1: Refer to unreadCountModel from threadModel
Suppose there is not message bus (Dispatcher). The views listen to stores and stores listens to action creators. (Note, there other way to do so, for example update Views via Controller, but the point here is to show the complexity for populating changes across models).
// in threadModel
...
var unreadCountModel = unreadCountModel();
return {
setAsRead: function(id) {
_.forEach(threadArray, function(thread) {
if (thread.id === id) {
thread.read = true;
}
})
updateUnreadCountModel();
},
updateUnreadCountModel: function () {
var unreadCount = _.filter(threadArray, function(thread) {return !thread.read;}).size();
unreadCountModel.setUnreadNumber(unreadCount);
}
}
...
It is not SO difficult, but it would be more tricky if within setUnreadNumber, we need to update the threadModel - typical circel dependency problem.
Option 2: Dispatcher
Of course, we will spend some time explaining how Dispatcher can address this problem.
// in threadModel
onAction: function(action) {
if (action.type === 'MARK_AS_READ') {
_.forEach(threadArray, function(thread) {
if (thread.id === action.payload.id) {
thread.read = true;
}
}
}
// in unreadCountModel
onAction: function(action) {
if (action.type === 'MARK_AS_READ') {
unreadCount = _.filter(threadArray, function(thread) {return !thread.read;}).size();
}
}
Conclusion
While we have been told that Model is stable than View, we have to acknowledge that some models are ViewModels. It is equally likely to change. Having a 1 to 1 map between Model and View makes more sense.
Technically speaking, Dispatcher is a singleton object which in OOD is a smell. However, I do not see a problem here. It just simplies the design. It works like a message bus and it should be a singleton, right?